In this post, we will discuss the concepts surrounding the topic “Regular Languages” like DFA, NFA, regular expressions, and two important theorems, the pumping lemma and Myhill-Nerode theorem.
Finite automaton
A good representation for what is so called finite automaton is a directed graph with a finite number of vertices. Each vertex is called a state. Each edge is assigned with a value called a symbol. The set of all possible symbols is called an alphabet. There is also one node marked as the start state, and some nodes are marked as the accept states. We give this automaton a string s, the following will happen:
1
2
3
4
5
current_state = start_state
for character ch in s:
for edge e in current_state.out_edges:
if e == ch:
current_state = e.end_node
You may wonder, what if there are multiple e such that e == ch? Well, this is the formal definition of finite automaton:
Definition: (Deterministic) Finite Automaton. A finite automaton is a tuple \((Q, \Sigma, \delta, q_0, F)\), where:
- \(Q\) is a finite set of states
- \(\Sigma\) is a finite set called the alphabet
- \(\delta: Q\times\Sigma\rightarrow Q\) is the transition function
- \(q_0\) is the start state
- \(F\) is the set of accept (final) states
Based on the definition of \(\delta\), you will always find at most one outgoing edge whose symbol concides with the character in the string. Such behavior is called “deterministic”, but we will discuss later.
If after browsing through all the characters in s, you end up with a current_state that can be found in \(F\), we say the automaton accepts s.
Let’s name our automaton (also called “machine”) \(M\). The set \(A\) of all strings that \(M\) accepts is called the language of machine \(M\) and written \(A = L(M)\). We also say \(M\) recognizes \(A\). \(A\) is unique to \(M\), i.e. one machine recognizes exactly one language. A language is called a regular language if there is some machine that recognizes it.
One common problem is to design an automaton that recognizes a given language. This is very similar to designing an algorithm. The automaton must accept all strings in the language, and reject any string not in the language.
For example, let \(A\) be the language over \(\Sigma=\{0,1\}\) which consists of all strings that have “0110” as a substring. Let’s design a simple algorithm first.
1
2
3
4
5
6
7
8
9
10
11
12
13
bool f(string s):
t = "0110"
for (int i = 0; i < s.size(); ++i):
// A
if (s[i] == '0'): // B
if (s[i+1] == '1'): // C
if (s[i+2] == '1'): // D
if (s[i+3] == '0'): // E
return true
else: continue
else: continue
else: continue
else: continue
Notice that I mark some lines as A, B, C, … They will be the states of our automaton, the states that we care. Before the for-loop, I don’t mark any state because it is unnecessary. Now we should find the transition function, i.e. when to change from this state to another state.
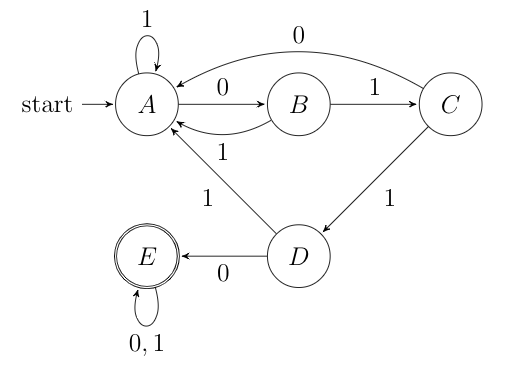
The automaton that recognizes the language of all strings that contain 0110 as a substring
- \(\delta(A, 0) = B\)
- \(\delta(A, 1) = A\)
- \(\delta(B, 0) = A\)
- \(\delta(B, 1) = C\)
- \(\delta(C, 0) = A\)
- \(\delta(C, 1) = D\)
- \(\delta(D, 0) = E\)
- \(\delta(D, 1) = A\)
- \(\delta(E, 0/1) = E\)
Once we reach state \(E\), which is the final state, the automaton will continue to process the rest of the string. Since we are guaranteed that the string contains “0110” as a substring, the rest of the string is not important. Hence all outgoing edges of \(E\) will go back to itself.
Properties of regular languages
If \(A\) and \(B\) are regular languages, \(A\cup B\), \(A\circ B\), \(A^*\) are also regular languages. Hence, \(\cup\), \(\circ\), and \(^*\) (written from low to high priority in term of operator precedence) are called regular operators.
Non-determinism
When two or more outgoing edges of a node have the same label, we call the automaton nondeterministic. Formally,
Definition: Nondeterministic Finite Automaton. An NFA is a tuple \((Q, \Sigma, \delta, q_0, F)\), where:
- \(Q\) is a finite set of states
- \(\Sigma\) is a finite set called the alphabet
- \(\delta: Q\times(\Sigma\ \cup\{\epsilon\})\rightarrow \mathcal{P}(Q)\) is the transition function
- \(q_0\) is the start state
- \(F\) is the set of accept (final) states
Note: \(\epsilon\) is the null character, also denotes the empty string.
Note: A DFA is automatically an NFA.
Hence when process a string, the following will happen:
1
2
3
4
5
6
7
8
current_state = {start_state}
for (character ch in s):
next_state = {} // empty list
for (state cs in current_state):
for (edge e in cs.out_edges):
if e == ch or e == epsilon:
next_state.add(e.end_node)
current_state = next_state
Theorem. Every NFA can be transformed into a DFA.
We can roughly understand why by looking at the algorithm. The current_state is now a subset of \(Q\), so our DFA should be a tuple \((\mathcal{P}(Q), \Sigma, \Delta, \{q_0\}, \{F\})\), where \(\Delta: \mathcal{P}(Q)\times \Sigma_\epsilon \rightarrow \mathcal{P}(Q)\). The rest of the proof is complicated to present, but should be obvious recognize, so I will stop here.
Regular expression
Regular expression is a way to generalize a language by exploiting its pattern. We use regular operators as operators, and symbols in the alphabet as operands, parentheses are allowed. For example, consider the language over \(\Sigma=\{0,1\}\) that contains all the strings that have 0110 as a substring, the expression can be written as:
\[\Sigma^*(0110)(0\cup 1)^*\]The concatenation operator is sometimes omitted just as the multiplication operator in arithmetic. \(\Sigma\) is just another way of writing \((0\cup 1)\) which is the short-hand writing of \((\{0\}\cup\{1\})\).
Theorem. Any finite automaton can be transformed into a regular expression and vice versa.
Generalized Nondeterministic Finite Automaton
Definition: Generalized Nondeterministic Finite Automaton. A GNFA is a tuple \((Q, \Sigma, \delta, q_{start}, q_{accept})\), where
- \(Q\) is a finite set of states
- \(\Sigma\) is a finite set called the alphabet
- \(\delta: (Q-\{q_{accept}\})\times(Q-\{q_{start}\})\rightarrow \mathcal{R}\) is the transition function
- \(q_{start}\) is the start state
- \(q_{accept}\) is the accept (final) state
A GNFA accepts a string \(w=w_1w_2\dots w_n\) where \(w_i\in \Sigma^*\) if there exists a list of \(n+1\) states \(q_0, q_2,\dots, q_n\) such that:
- \(q_0=q_{start}\)
- \(q_n=q_{accept}\)
- for each \(i\), we have \(w_i\in L(\delta(q_{i-1}, q_i))\)
In the graph representation of a GNFA, on each edge, instead of a symbol, there is a regular expression. You move from state to state over an edge if the next few letters in the input string fit the regular expression on that edge.
However, it can be shown that any GNFA that has more than 2 states can be transformed into a GNFA with exactly 2 states. We just need to remove the states sequentially, each time we remove a state, we need to redraw our edges. Suppose that we are removing \(q_r\), we need to bridge all pair of \(q_i\) and \(q_j\), where \(q_i\) denotes the state that goes into \(q_r\) via an edge and \(q_j\) denotes the state into which \(q_r\) goes via an edge. What regular expression could we assign for our edge \((q_i, q_j)\)? We need to think: how many ways can we go from \(q_i\) to \(q_j\)?
- Go directly if there exists an edge between them already.
- Go from \(q_i\) to \(q_r\), self-loop at \(q_r\) for an arbitrary number of times, then go from \(q_r\) to \(q_j\).
which implies that:
\[\delta(q_i, q_j) := \delta(q_i, q_j)\cup \delta(q_i, q_r)\delta(q_r, q_r)^*\delta(q_r, q_j)\]Note: I used := for simple writing, that means we redefine the mapping between \(q_i\) and \(q_j\). You can always define a completely new GNFA so that it will look more formal, more mathematical, and less programming.
Eventually you will end up with a GNFA that contains only \(q_{start}\) and \(q_{accept}\). Based on the source set of \(\delta\), there should be no self loop at any of these two states, i.e. there is only one edge on this graph. The expression on this graph is the regular expression representation of the original GNFA.
Note that a DFA or an NFA is automatically an GNFA, so the algorithm above can also give us the regular expression of the automaton.
Pumping lemma
You may have heard of “Squeeze theorem”, định lý kẹp.
Now introducing “Pumping lemma”, bổ đề bơm.
Theorem: Pumping lemma. Let A be a regular language. There exists a number \(p\) such that any string \(s\in A\) whose length \(\geq p\) can be divided into three parts \(s = xyz\) satisfying the following conditions:
- for any \(i\geq 0\), \(xy^iz\in A\)
- \(y \neq \epsilon\)
- \(\vert xy\vert \leq p\)
If A is a finite language, it vacuously satisfies the pumping lemma by choosing \(p\) larger than the size of the longest string in A.
Proof idea
Since \(A\) is regular, there’s a DFA that recognizes it. Let \(p\) be the number of states in the automaton.
For a string of length at least \(p\), it must go through \(p+1\) states as the string is emitted. By the pigeonhole principle, it must have reached some state at least twice. The substring that corresponds to the journey from the first appearance to the second appearance of the repeated state is \(y\) in the lemma. Hence, we can travel in this loop for an arbitrary number of times, or none at all, and can still reach one of the accept state.
Nonregular language
The fact that mathematicians use the phrase “nonregular language” instead of “irregular language” annoys me so much I want to quit my study.
(Please write that quote on my tomb when I die)
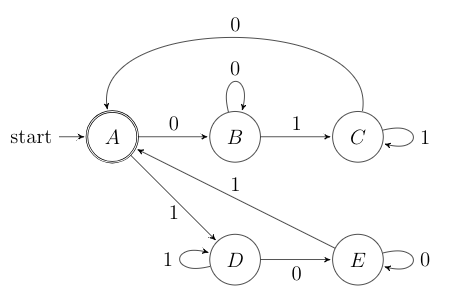
The DFA that recognizes the language of all strings containing equal occurences of 01 and 10 as substrings.
Finite automata have limited memory, i.e. finite amount of states, and they cannot recognize language that require infinite states. A famous example is the language \(\{0^n1^n \vert\ n\geq 0\}\). This language is nonregular because it has to remember how many 0’s it has read before reading the 1’s. There is no upper limit to \(n\), hence it requires infinitely many states.
On the other hand, the language of all strings that have an equal number of occurences of 01 and 10 seems like a nonregular because it may have to count the occurences, which can tend to infinity. However it is not necessary to count. Whenever you approach a substring 01 (state C), just wait until you get a 0, then the amounts are balanced. Vice versa, if you approach a substring 10 (state E), just wait until you get a 1. This language is regular.
We usually use the pumping lemma to prove a language to be nonregular by contradiction.
The class of regular languages
I’ve mentioned that three operators \(\cup, ^*, \circ\) are regular operators, i.e. if A and B are regular languages, then so are \(A\cup B, A^*, A\circ B\). The class of regular languages, however, is also closed under other “operators”:
- Perfect shuffle of A and B is the language of all strings \(a_1b_1\dots a_nb_n\) where \(a_1\dots a_n\in A\) and \(b_1\dots b_n\in B\) and \(a_i, b_i\in\Sigma\).
- Shuffle of A and B is the language of all strings \(a_1b_1\dots a_nb_n\) where \(a_1\dots a_n\in A\) and \(b_1\dots b_n\in B\) and \(a_i, b_i\in\Sigma^*\).
- Reverse of a string is obtained by rewriting its character in the opposite order. Reverse of a language is obtained by reversing each string in the language, i.e. \(A^{\mathcal{R}}=\{w^{\mathcal{R}}\vert w\in A\}\)
- ……….
Finite-state Transducer
A finite-state transducer (FST) is an extension of DFA that not only returns “accept” or “reject”, but also outputs a string as the input string is processed. Each transition is labelled with two symbols, one specifying the input symbol and the other specifying the output symbol.
1
2
3
4
5
6
7
current_state = start_state
output_string = "" // empty
for character ch in s:
for edge e in current_state.out_edges:
if e.input_symbol == ch:
current_state = e.end_node
output_string.add(e.output_symbol)
This means that, it follows the exact process as if it is the DFA, but at each transition it gives us an output symbol. The output symbol does NOT affect the traversal. Think of it as a debugger and you are writing to the screen the value of some variable.
Myhill-Nerode Theorem
Let \(x,y\) be two strings in the language \(L\).
- We say that \(x\) and \(y\) are distinguishable by \(L\) if some string \(z\) (can be empty) exists and one of the strings \(xz\) and \(yz\) is in \(L\), but not both. In this case, \(z\) is called the distinguish extension.
- We say that they are indistinguishable by \(L\) if for any string \(z\) we have “\(xz\in L\Leftrightarrow yz\in L\)”. If \(x\) and \(y\) are indistinguishable by \(L\), we write \(x\equiv_L y\).
Note: x and y are not necessarily in L. They are in fact any strings made from the alphabet \(\Sigma\) on which L is based, i.e. \(x,y\in\Sigma^*\).
Theorem. \(\equiv_L\) is an equivalence relation.
which implies that \(\equiv_L\) divides \(\Sigma^*\) into equivalence classes. We call them the equivalence classes of \(\equiv_L\). The index of \(L\) is the number of equivalence classes. The index can be infinite or finite.
Properties:
- If \(x\equiv_L y\) then \(xz\equiv_L yz, \forall z\). It is true because if xz and yz are distinguishable, say w is the distinguish extension, hence either xzw or yzw belongs to L but not both. \(\Rightarrow\) zw is the distinguish extension for x and y, which contradicts to the assumption \(x\equiv_L y\).
- If \(x\equiv_L y\) and \(x\in L\) then \(y\in L\). It is true because if \(y\notin L\), x and y are distinguishable when choose the empty string as the distinguish extension, which contradicts to the assumption \(x\equiv_L y\).
Theorem: Myhill-Nerode Theorem. \(L\) is regular iff it has finite index, and its index is the number of states in the DFA recognizing it.
▶ Proof
1. Prove that if L is recognized by some DFA with n states, then its index is at most n.
We partition \(\Sigma^*\) into n sets, set \(S_i\) contains all the strings that when given to A will cause A to stop at state i. It can be seen that, if x and y are in the same set \(S_i\), for any string z, xz and yz will cause A to stop at the same state, and therefore both of them are either rejected or accepted, i.e. \(x\equiv_L y\) (though, it is possible for some strings x and y of different sets to be equivalent by L). In conclusion, \(S_i\) is a subset of an equivalence class.
Consider the map from the set of n sets \(S_i\), to the set of equivalence classes of \(\equiv_L\). Any string x belongs to some set \(S_i\) and belongs to some equivalence class of \(\equiv_L\), this means any equivalence class has a pre-image, i.e. the map is surjective. \(\Rightarrow\) The number of equivalence classes does not exceed n, the number of states.
2. Prove that if the index of \(L\) is a finite number n, it is recognized by a DFA with n states.
We have \(\Sigma^*\) divided into n equivalence classes. It is possible to construct a DFA such that if string x is from the class i, the automaton shall stop at state i, in that case we say the string x corresponds (just a made-up word) to state i. The construction of transitions can be shown recursively:
- State i is the start state if class i has the empty string. Note that there is only one such state.
- The transition from some state i to state j on the input symbol y if for an arbitrary string x corresponding to state i, xy corresponds to state j. It doesn’t matter which x is chosen, because we’ve shown that if \(x_1\equiv_L x_2\) then \(x_1y\equiv_L x_2y, \forall y\), so the next state will always be the same regardless of x.
- State i is an accept state if class i contains a string that belongs to L. In fact, we’ve shown in the properties section that if it contains a string in L, then all other strings in this class are also in L.
We can continue by proving this DFA recognizes L, but I would just stop here.
3. Conclusion
Combining the two results above gives us the Myhill-Nerode theorem.
Reference source
- Wikipedia - Myhill-Nerode Theorem
- Michael Sipser - “Introduction to the Theory of Computation” (3rd ed.)
- Wikipedia - Pumping Lemma for Regular Languages